
Reasoning Embedding
Collection
The official collection of the paper "Do Reasoning Models Enhance Embedding Models"?
•
59 items
•
Updated
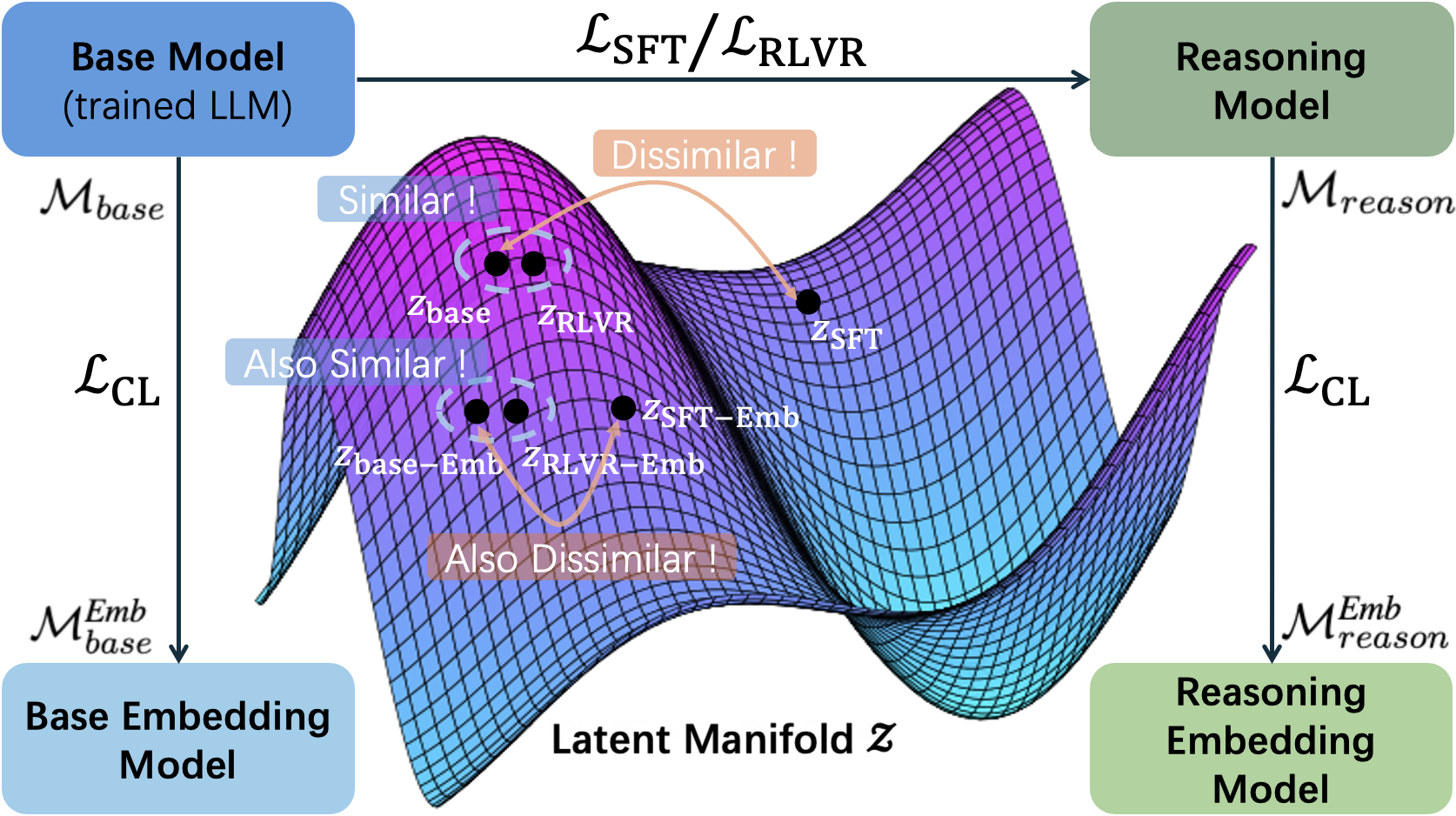
State-of-the-art embedding models are increasingly derived from decoder-only Large Language Model (LLM) backbones adapted via contrastive learning. Given the emergence of reasoning models trained via Reinforcement Learning with Verifiable Rewards (RLVR), a natural question arises: do enhanced reasoning translate to superior semantic representations when these models serve as embedding initializations? Contrary to expectation, our evaluation on MTEB and BRIGHT reveals a null effect: embedding models initialized from RLVR-tuned backbones yield no consistent performance advantage over their base counterparts when subjected to identical training recipes. To unpack this paradox, we introduce Hierarchical Representation Similarity Analysis (HRSA), a framework that decomposes similarity across representation, geometry, and function levels. HRSA reveals that while RLVR induces irreversible latent manifold's local geometry reorganization and reversible coordinate basis drift, it preserves the global manifold geometry and linear readout. Consequently, subsequent contrastive learning drives strong alignment between base- and reasoning-initialized models, a phenomenon we term Manifold Realignment. Empirically, our findings suggest that unlike Supervised Fine-Tuning (SFT), RLVR optimizes trajectories within an existing semantic landscape rather than fundamentally restructuring the landscape itself.
If you received the following error (or something like that):
[ERROR] `is_causal` is part of Qwen3Model.forward's signature, but not documented. Make sure to add it to the docstring of the function in /.../modeling_qwen3.py.
Just ignore it. It's even a good sign to indicate your success in setting up the bidirectional attention.
Remember to set trust_remote_code=True.
# Requires transformers>=5.0.0.
# Requires sentence-transformers>=5.0.0
from sentence_transformers import SentenceTransformer
# Load the model
model = SentenceTransformer("lucaswychan/Qwen3-0.6B-Base-checkpoint-200-Reasoning-Embedding", trust_remote_code=True, model_kwargs={"attn_implementation": "flash_attention_2", "device_map": "cuda"})
# The queries and documents to embed
queries = [
"What is the capital of China?",
"Explain gravity",
]
# No need to add prompt to the documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun.",
]
# Encode the queries and documents. Note that queries benefit from using a prompt
# Here we use the prompt called "query" stored under `model.prompts`, but you can
# also pass your own prompt via the `prompt` argument
query_embeddings = model.encode(queries, prompt_name="query")
document_embeddings = model.encode(documents)
# Compute the (cosine) similarity between the query and document embeddings
similarity = model.similarity(query_embeddings, document_embeddings)
print(similarity)
Remember to set trust_remote_code=True.
# Requires transformers>=5.0.0.
# Requires sentence-transformers>=5.0.0
import torch.nn.functional as F
from torch import Tensor
from transformers import AutoTokenizer, AutoModel
def average_pool(last_hidden_states: Tensor,
attention_mask: Tensor) -> Tensor:
last_hidden = last_hidden_states.masked_fill(~attention_mask[..., None].bool(), 0.0)
return last_hidden.sum(dim=1) / attention_mask.sum(dim=1)[..., None]
def get_detailed_instruct(task_description: str, query: str) -> str:
return f'Instruct: {task_description}\nQuery: {query}'
# Each query must come with a one-sentence instruction that describes the task
task = 'Given a web search query, retrieve relevant passages that answer the query'
# The queries and documents to embed
queries = [
get_detailed_instruct(task, "What is the capital of China?"),
get_detailed_instruct(task, "Explain gravity"),
]
# No need to add prompt to the documents
documents = [
"The capital of China is Beijing.",
"Gravity is a force that attracts two bodies towards each other. It gives weight to physical objects and is responsible for the movement of planets around the sun.",
]
tokenizer = AutoTokenizer.from_pretrained("lucaswychan/Qwen3-0.6B-Base-checkpoint-200-Reasoning-Embedding")
model = AutoModel.from_pretrained("lucaswychan/Qwen3-0.6B-Base-checkpoint-200-Reasoning-Embedding", trust_remote_code=True, attn_implementation="flash_attention_2", device="cuda")
# Tokenize the input texts
query_inputs = tokenizer(queries, max_length=512, padding=True, truncation=True, return_tensors='pt').to(model.device)
document_inputs = tokenizer(documents, max_length=512, padding=True, truncation=True, return_tensors='pt').to(model.device)
# Run the forward pass for both of the inputs
query_outputs = model(**query_inputs)
document_outputs = model(**document_inputs)
# Pool the last hidden states with mean pooling
query_embeddings = average_pool(query_outputs.last_hidden_state, query_inputs['attention_mask'])
document_embeddings = average_pool(document_outputs.last_hidden_state, document_inputs['attention_mask'])
# normalize embeddings
query_embeddings = F.normalize(query_embeddings, p=2, dim=1)
document_embeddings = F.normalize(document_embeddings, p=2, dim=1)
scores = (query_embeddings @ document_embeddings.T) * 100
print(scores.tolist())
If you have used our models and datasets, please cite our paper:
@misc{chan2026reasoningmodelsenhanceembedding,
title={Do Reasoning Models Enhance Embedding Models?},
author={Wun Yu Chan and Shaojin Chen and Huihao Jing and Kwun Hang Lau and Elton Chun-Chai Li and Zihao Wang and Haoran Li and Yangqiu Song},
year={2026},
eprint={2601.21192},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2601.21192},
}
Lucas Wun Yu CHAN
lucaswychanlc@gmail.com / wychanbu@connect.ust.hk
Base model
Qwen/Qwen3-0.6B-Base