Datasets:

pretty_name: t2ranking-hard-neg-reasoning-embedding
tags:
- jsonl
- retrieval
- similarity
- hard-negative
- reasoning-embedding
task_categories:
- text-retrieval
- sentence-similarity
license: apache-2.0
language:
- multilingual
Introduction
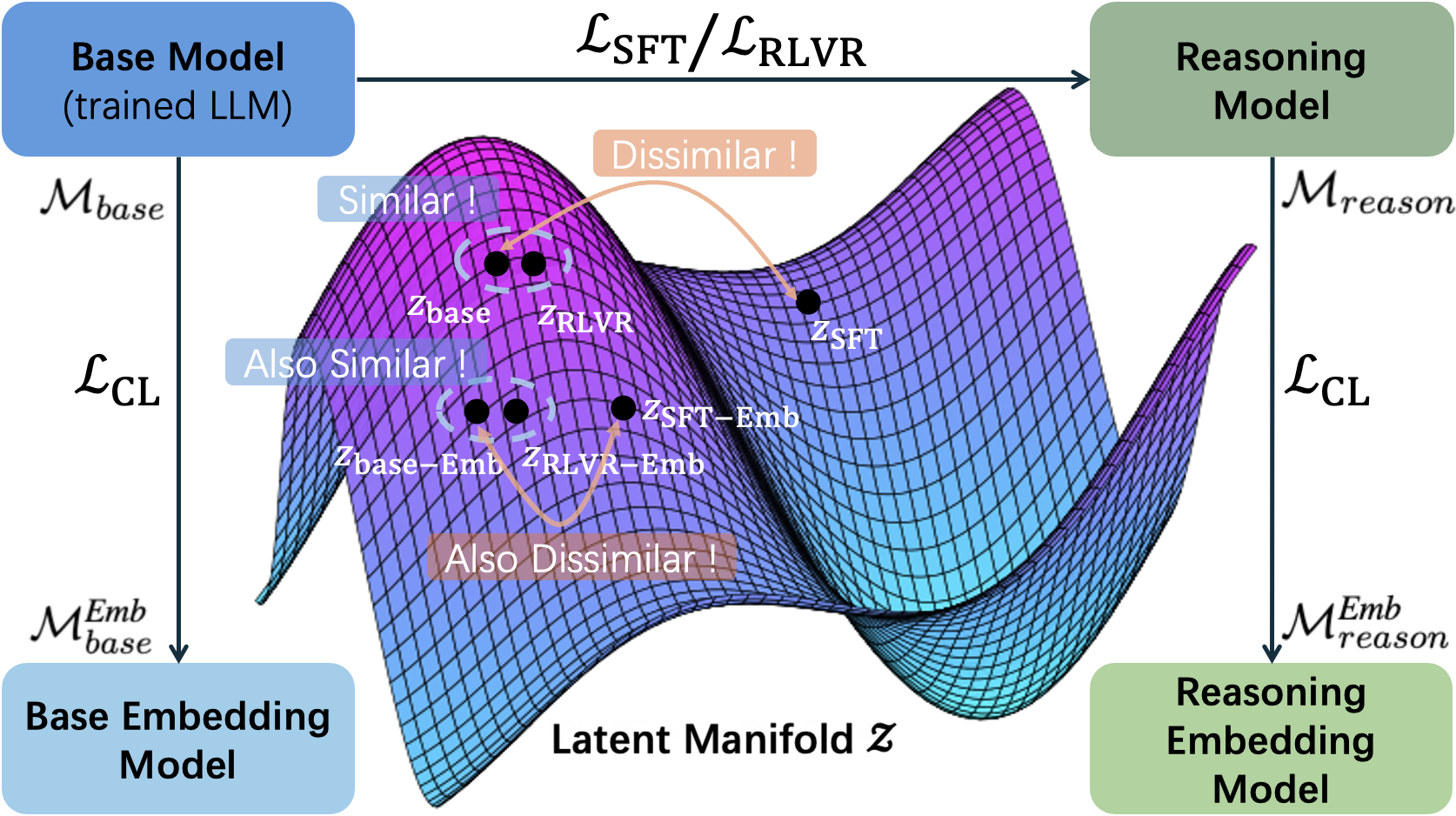
This is the dataset used to train the embedding models in the paper Do Reasoning Models Enhance Embedding Models?. We use Qwen3-Embedding-0.6B to mine 3 hard negatives per query, and employ the positive-aware hard negative mining technique introduced in NV-Retriever with 95% margin to the positive score.
Abstract
State-of-the-art embedding models are increasingly derived from decoder-only Large Language Model (LLM) backbones adapted via contrastive learning. Given the emergence of reasoning models trained via Reinforcement Learning with Verifiable Rewards (RLVR), a natural question arises: do enhanced reasoning translate to superior semantic representations when these models serve as embedding initializations? Contrary to expectation, our evaluation on MTEB and BRIGHT reveals a null effect: embedding models initialized from RLVR-tuned backbones yield no consistent performance advantage over their base counterparts when subjected to identical training recipes. To unpack this paradox, we introduce Hierarchical Representation Similarity Analysis (HRSA), a framework that decomposes similarity across representation, geometry, and function levels. HRSA reveals that while RLVR induces irreversible latent manifold's local geometry reorganization and reversible coordinate basis drift, it preserves the global manifold geometry and linear readout. Consequently, subsequent contrastive learning drives strong alignment between base- and reasoning-initialized models, a phenomenon we term Manifold Realignment. Empirically, our findings suggest that unlike Supervised Fine-Tuning (SFT), RLVR optimizes trajectories within an existing semantic landscape rather than fundamentally restructuring the landscape itself.
Dataset Structure
The dataset is structured according to the GritLM repository's format: {"query": List[str], "pos": List[str], "neg": List[str]}. The script to mine the hard negatives is here.
query: This is a list containing two strings.query[0]holds the instruction. A complete list of instructions can be found here.query[1]contains the actual query text.
pos: A list with a single string, representing the positive anchor for the query. You can add more anchors to the list.neg: A list containing 1 - 3 strings, which are the mined hard negatives associated with the query.
For example,
{
"query": [
"Instruct: Given a premise, retrieve a hypothesis that is entailed by the premise\nQuery: ",
"A woman wearing a green and pink dress is dancing with someone wearing a blue top with white pants."
],
"pos": [
"The woman in green and pink is dancing."
],
"neg": [
"The dancing woman is alone in her bedroom.",
"A woman in a dress dances with a man.",
"A woman wearing a green belly dancing outfit is near a man and woman who are seated"
]
}
🚀 Quick Start
from datasets import load_dataset
dataset = load_dataset("lucaswychan/t2ranking-hard-neg-reasoning-embedding")
📚 Citation
If you have used our models and datasets, please cite our paper:
@misc{chan2026reasoningmodelsenhanceembedding,
title={Do Reasoning Models Enhance Embedding Models?},
author={Wun Yu Chan and Shaojin Chen and Huihao Jing and Kwun Hang Lau and Elton Chun-Chai Li and Zihao Wang and Haoran Li and Yangqiu Song},
year={2026},
eprint={2601.21192},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2601.21192},
}
📞 Contact
Lucas Wun Yu CHAN
lucaswychanlc@gmail.com / wychanbu@connect.ust.hk