
Malaysian SFT
Collection
SFT using LoRA and DoRA including reasoning. • 9 items • Updated
SFT LoRA Qwen/Qwen3-235B-A22B-Instruct-2507 on Scicom-intl/Malaysian-Instructions/commit/288b358a57765a735d588f73e5e6c212c81429bd
+ with the rank of each equal to the total rank divided by the number of active experts, https://thinkingmachines.ai/blog/lora/
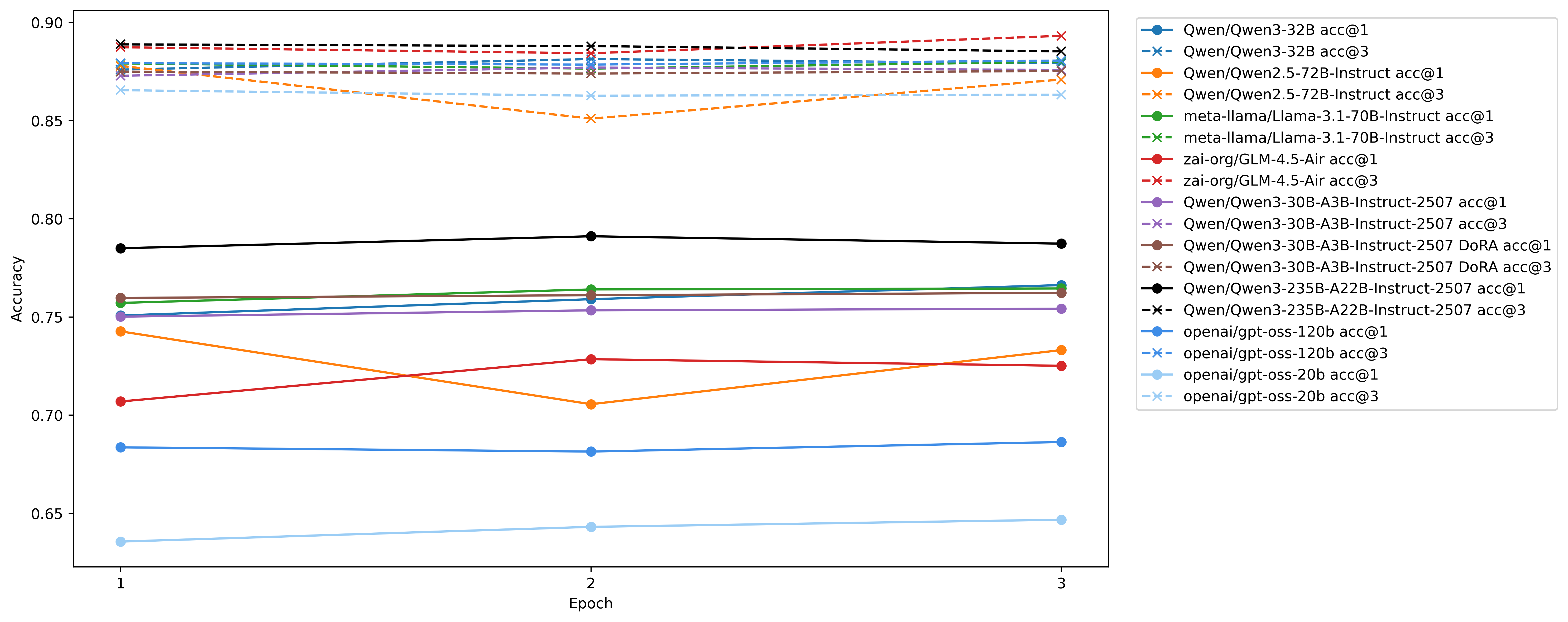
Source code at https://github.com/Scicom-AI-Enterprise-Organization/small-ablation/blob/main/malaysian-sft
Special thanks to https://www.scitix.ai/ for H100 Node!