---
license: agpl-3.0
datasets:
- biglam/loc_beyond_words
base_model:
- Ultralytics/YOLO11
pipeline_tag: object-detection
tags:
- glam
- lam
- history
- newspapers
---
# Beyond Words Visual Content Detector
This family of YOLO object detection models detects and classifies seven types of visual content in historical newspaper pages from the Library of Congress's _Chronicling America_ collection.
Trained on the crowdsourced **Beyond Words** dataset these models identify:
- Photographs
- Illustrations
- Maps
- Comics/Cartoons
- Editorial Cartoons
- Headlines
- Advertisements
## Example Outputs
Below are two examples of the model's output. The first is an example from the training data, and the second is an example of the model's performance on an out-of-domain (OoD) image.
 _Objects detected for an example from the training data_
_Objects detected for an example from the training data_
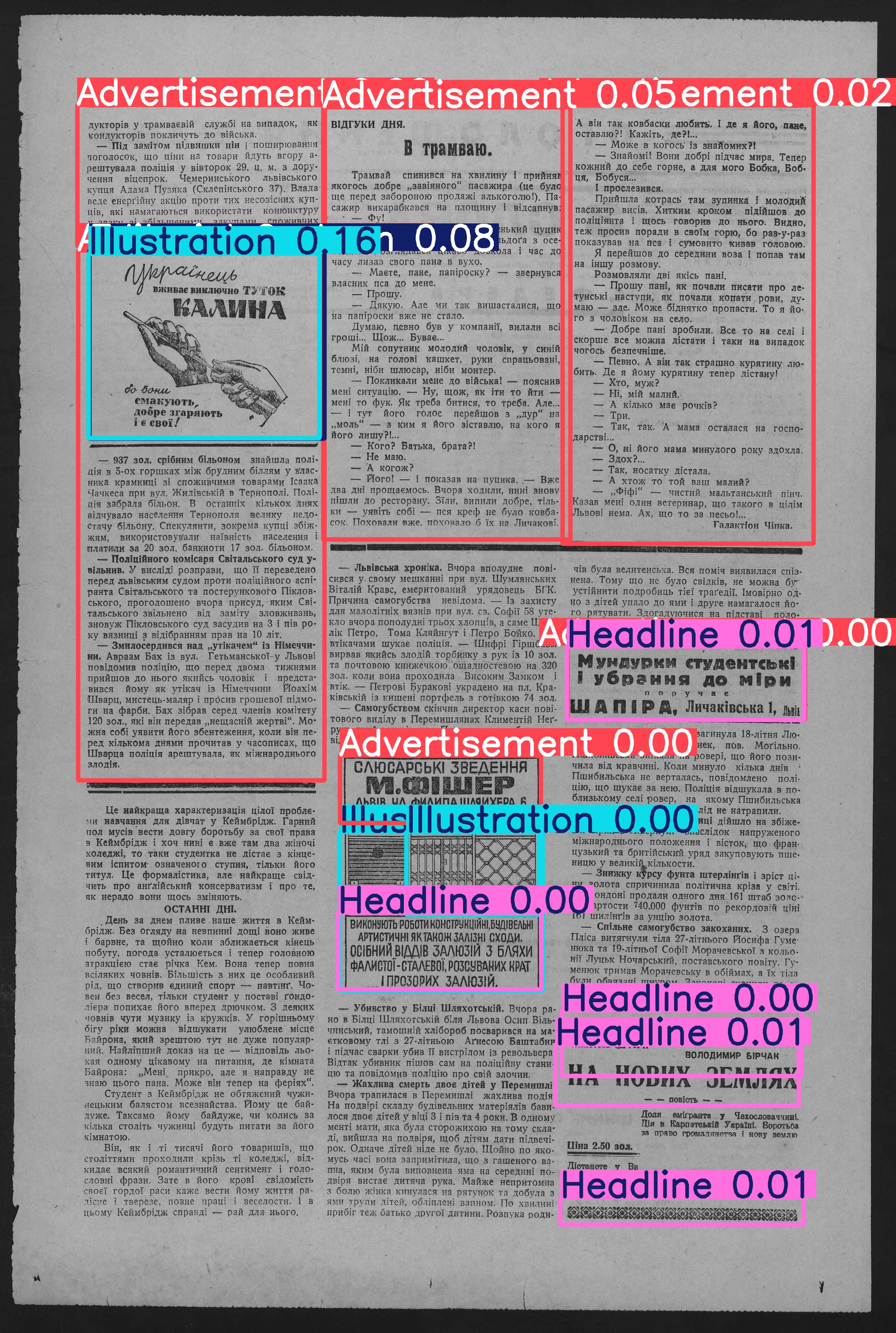 _Objects detected for an in the "wild" newspaper example_
## 🚀 Quick Start
### Installation
```bash
pip install ultralytics huggingface_hub
```
### Inference
```python
from huggingface_hub import hf_hub_download
from ultralytics import YOLO
# Download and load nano model
model = YOLO(hf_hub_download(
repo_id="small-models-for-glam/historic-newspaper-illustrations-yolov11",
filename="yolo11n.pt"
))
# Or download and load small model
model = YOLO(hf_hub_download(
repo_id="small-models-for-glam/historic-newspaper-illustrations-yolov11",
filename="yolo11s.pt"
))
# Run inference on an image
results = model("path/to/newspaper_page.jpg")
# Process results
for result in results:
boxes = result.boxes # Boxes object for bbox outputs
for box in boxes:
# Get box coordinates
x1, y1, x2, y2 = box.xyxy[0]
# Get confidence score
conf = box.conf[0]
# Get class
cls = box.cls[0]
# Get class name
class_name = model.names[int(cls)]
print(f"Detected {class_name} with confidence {conf:.2f}")
```
## 📰 Use Case
The model is intended to extract visual content from historical newspapers.
## 📊 Dataset
The models were trained on the [Beyond Words dataset](https://labs.loc.gov/work/experiments/beyond-words/), which was created via crowdsourcing and augmented with expert-labelled annotations for headlines and advertisements. The dataset consists of:
- 3,559 annotated newspaper pages (train+val)
- 48,409 labelled visual content regions
- 7 content categories
Annotations are provided in COCO format and were aligned with METS/ALTO OCR for further downstream use.
It's important to note that the training data does not represent a representative sample of historical newspaper content. The training data is drawn from the Library of Congress's _Chronicling America_ collection, which is focused on American newspapers from the late 19th and early 20th centuries. This also means that the models are likely to do much better on images from this period and digitised similarly.
## 🧠 Model Details
All models are fine-tuned variants of the YOLO11 object detection architecture. The training set consisted of high-resolution historical newspaper scans from WWI-era publications, with performance validated on a held-out set of 712 pages.
### 🔎 Performance Metrics
| Class | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 |
| ------------------- | --------- | ------ | ------- | ------------ |
| Photograph | 0.995 | 0.976 | 0.987 | 0.958 |
| Illustration | 0.990 | 0.969 | 0.983 | 0.929 |
| Map | 0.978 | 0.971 | 0.979 | 0.945 |
| Comics/Cartoon | 0.994 | 0.967 | 0.975 | 0.952 |
| Editorial Cartoon | 1.000 | 0.984 | 0.995 | 0.985 |
| Headline | 0.987 | 0.996 | 0.995 | 0.895 |
| Advertisement | 0.994 | 0.998 | 0.995 | 0.956 |
| **Overall (macro)** | 0.991 | 0.980 | 0.987 | 0.946 |
## 🧪 Model Variants
_Objects detected for an in the "wild" newspaper example_
## 🚀 Quick Start
### Installation
```bash
pip install ultralytics huggingface_hub
```
### Inference
```python
from huggingface_hub import hf_hub_download
from ultralytics import YOLO
# Download and load nano model
model = YOLO(hf_hub_download(
repo_id="small-models-for-glam/historic-newspaper-illustrations-yolov11",
filename="yolo11n.pt"
))
# Or download and load small model
model = YOLO(hf_hub_download(
repo_id="small-models-for-glam/historic-newspaper-illustrations-yolov11",
filename="yolo11s.pt"
))
# Run inference on an image
results = model("path/to/newspaper_page.jpg")
# Process results
for result in results:
boxes = result.boxes # Boxes object for bbox outputs
for box in boxes:
# Get box coordinates
x1, y1, x2, y2 = box.xyxy[0]
# Get confidence score
conf = box.conf[0]
# Get class
cls = box.cls[0]
# Get class name
class_name = model.names[int(cls)]
print(f"Detected {class_name} with confidence {conf:.2f}")
```
## 📰 Use Case
The model is intended to extract visual content from historical newspapers.
## 📊 Dataset
The models were trained on the [Beyond Words dataset](https://labs.loc.gov/work/experiments/beyond-words/), which was created via crowdsourcing and augmented with expert-labelled annotations for headlines and advertisements. The dataset consists of:
- 3,559 annotated newspaper pages (train+val)
- 48,409 labelled visual content regions
- 7 content categories
Annotations are provided in COCO format and were aligned with METS/ALTO OCR for further downstream use.
It's important to note that the training data does not represent a representative sample of historical newspaper content. The training data is drawn from the Library of Congress's _Chronicling America_ collection, which is focused on American newspapers from the late 19th and early 20th centuries. This also means that the models are likely to do much better on images from this period and digitised similarly.
## 🧠 Model Details
All models are fine-tuned variants of the YOLO11 object detection architecture. The training set consisted of high-resolution historical newspaper scans from WWI-era publications, with performance validated on a held-out set of 712 pages.
### 🔎 Performance Metrics
| Class | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 |
| ------------------- | --------- | ------ | ------- | ------------ |
| Photograph | 0.995 | 0.976 | 0.987 | 0.958 |
| Illustration | 0.990 | 0.969 | 0.983 | 0.929 |
| Map | 0.978 | 0.971 | 0.979 | 0.945 |
| Comics/Cartoon | 0.994 | 0.967 | 0.975 | 0.952 |
| Editorial Cartoon | 1.000 | 0.984 | 0.995 | 0.985 |
| Headline | 0.987 | 0.996 | 0.995 | 0.895 |
| Advertisement | 0.994 | 0.998 | 0.995 | 0.956 |
| **Overall (macro)** | 0.991 | 0.980 | 0.987 | 0.946 |
## 🧪 Model Variants
yolo11n.pt (nano)
Trained for edge applications or fast inference.
**Results**
| Class | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 |
| ------------------- | --------- | ------ | ------- | ------------ |
| Photograph | 0.995 | 0.976 | 0.987 | 0.958 |
| Illustration | 0.990 | 0.969 | 0.983 | 0.929 |
| Map | 0.978 | 0.971 | 0.979 | 0.945 |
| Comics/Cartoon | 0.994 | 0.967 | 0.975 | 0.952 |
| Editorial Cartoon | 1.000 | 0.984 | 0.995 | 0.985 |
| Headline | 0.987 | 0.996 | 0.995 | 0.895 |
| Advertisement | 0.994 | 0.998 | 0.995 | 0.956 |
| **Overall (macro)** | 0.991 | 0.980 | 0.987 | 0.946 |
yolo11s.pt (small)
Balanced for speed and accuracy.
**Results**
| Class | Images | Instances | Box(P) | Box(R) | mAP50 | mAP50-95 |
| ----------------- | ------ | --------- | ------ | ------ | ----- | -------- |
| all | 711 | 9923 | 0.98 | 0.958 | 0.982 | 0.927 |
| Photograph | 488 | 875 | 0.986 | 0.947 | 0.982 | 0.941 |
| Illustration | 154 | 206 | 0.962 | 0.951 | 0.972 | 0.906 |
| Map | 32 | 34 | 0.966 | 0.941 | 0.973 | 0.937 |
| Comics/Cartoon | 109 | 211 | 0.985 | 0.942 | 0.968 | 0.923 |
| Editorial Cartoon | 53 | 54 | 1.000 | 0.967 | 0.995 | 0.973 |
| Headline | 617 | 5685 | 0.979 | 0.966 | 0.992 | 0.868 |
| Advertisement | 510 | 2858 | 0.985 | 0.989 | 0.994 | 0.939 |
## 📂 Training
The models were trained using PyTorch and Ultralytics YOLOv11 on annotated newspaper pages. OCR-aligned captions were included in bounding boxes when present. Data augmentation techniques include resizing and random flipping.
## 🧾 Citation
If you use this model or dataset, please cite the following:
### Model
```bibtex
@software{yolo11_ultralytics,
author = {Glenn Jocher and Jing Qiu},
title = {Ultralytics YOLO11},
version = {11.0.0},
year = {2024},
url = {https://github.com/ultralytics/ultralytics},
license = {AGPL-3.0}
}
```
### Dataset
```bibtex
@inproceedings{10.1145/3340531.3412767,
author = {Lee, Benjamin Charles Germain and Mears, Jaime and Jakeway, Eileen and Ferriter, Meghan and Adams, Chris and Yarasavage, Nathan and Thomas, Deborah and Zwaard, Kate and Weld, Daniel S.},
title = {The Newspaper Navigator Dataset: Extracting Headlines and Visual Content from 16 Million Historic Newspaper Pages in Chronicling America},
year = {2020},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
doi = {10.1145/3340531.3412767},
url = {https://doi.org/10.1145/3340531.3412767}
}
```
## License
This model is released under the AGPL-3.0 license. The dataset is licensed CC0 (Public Domain).